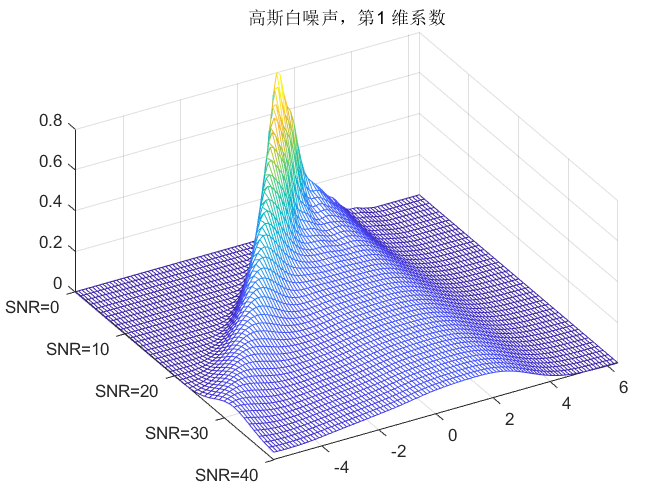
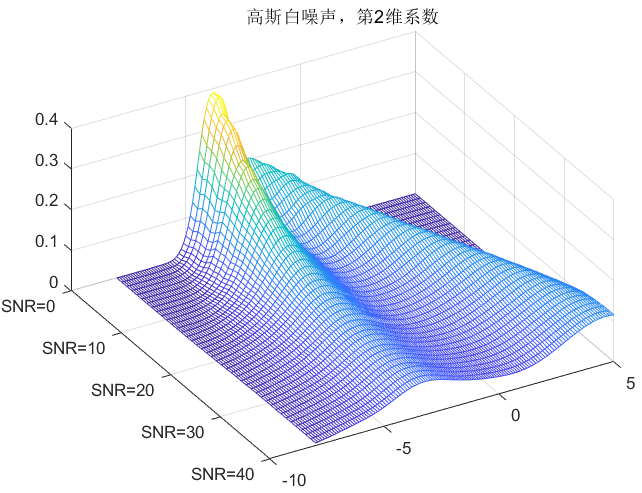
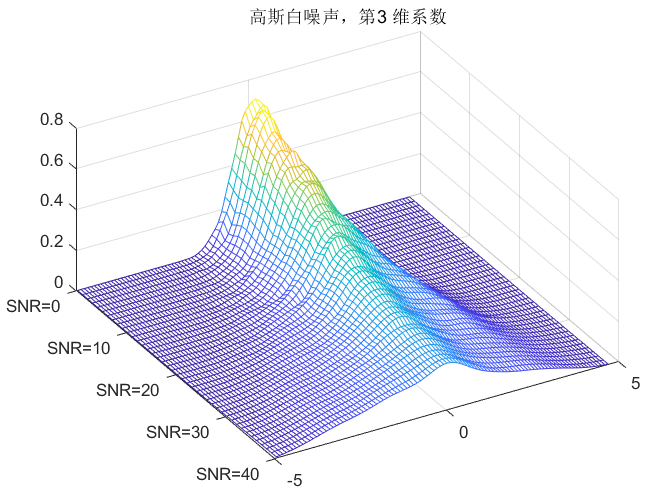
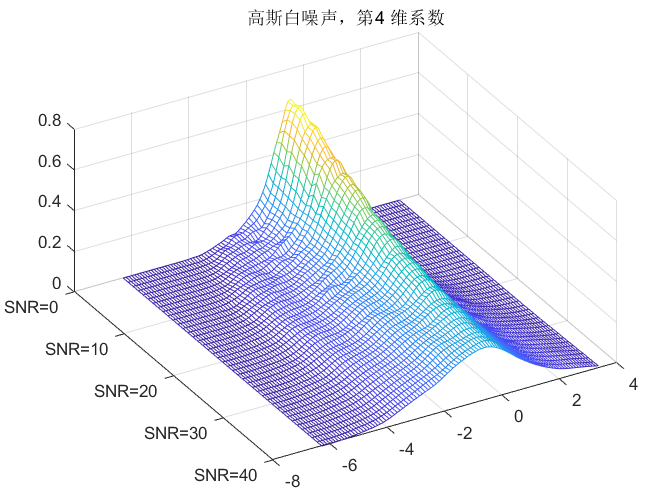
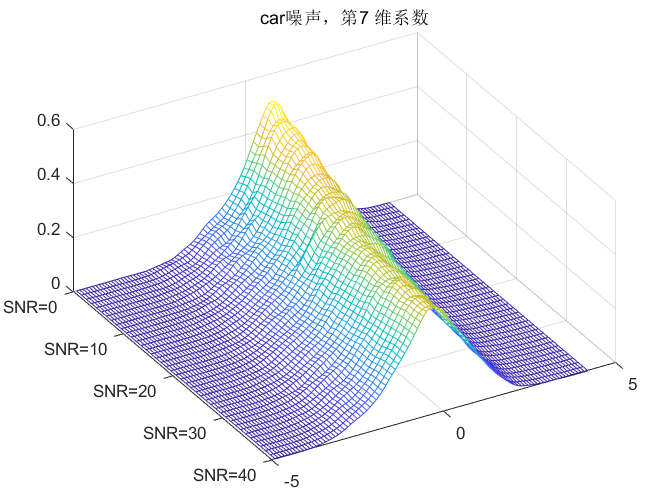
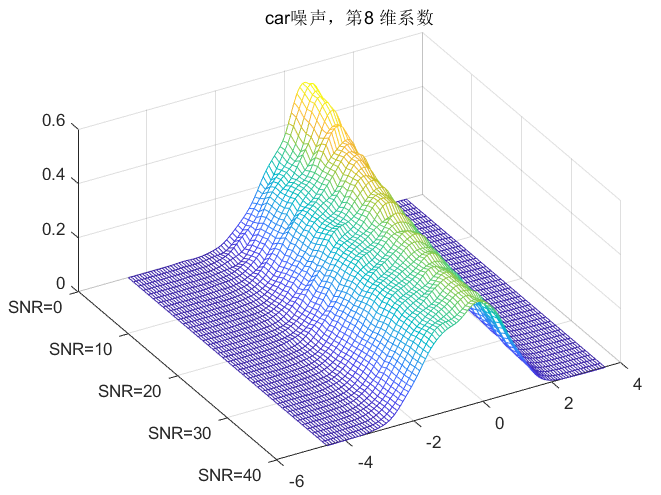
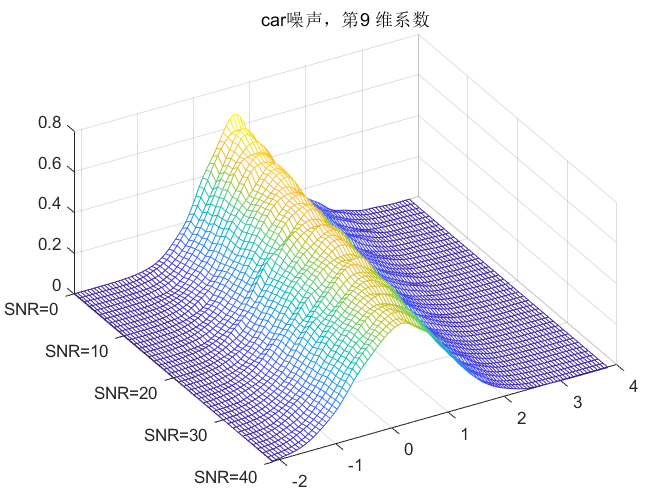
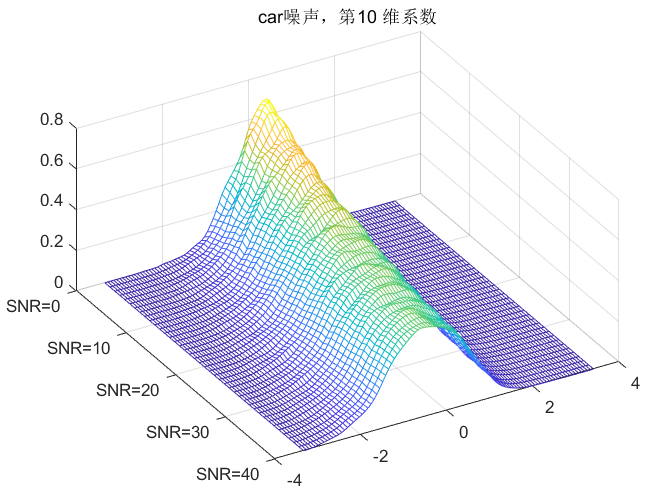
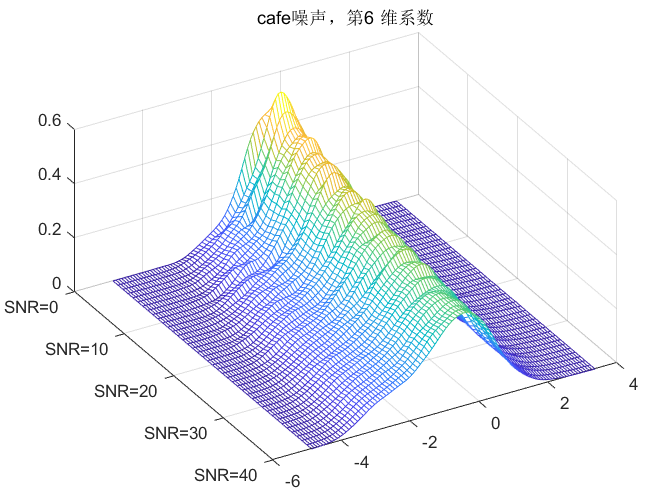
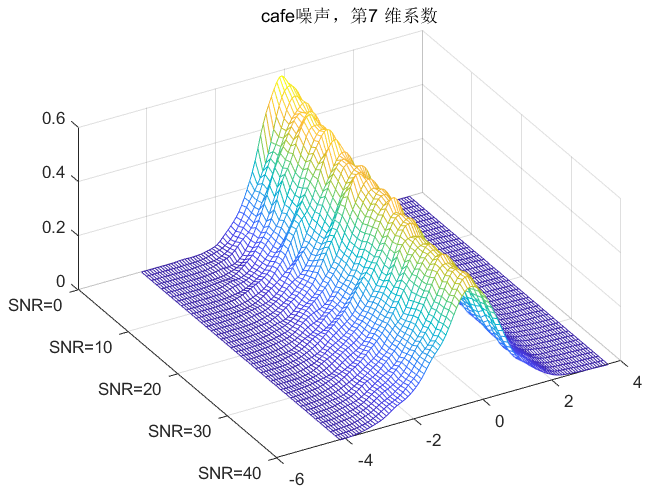
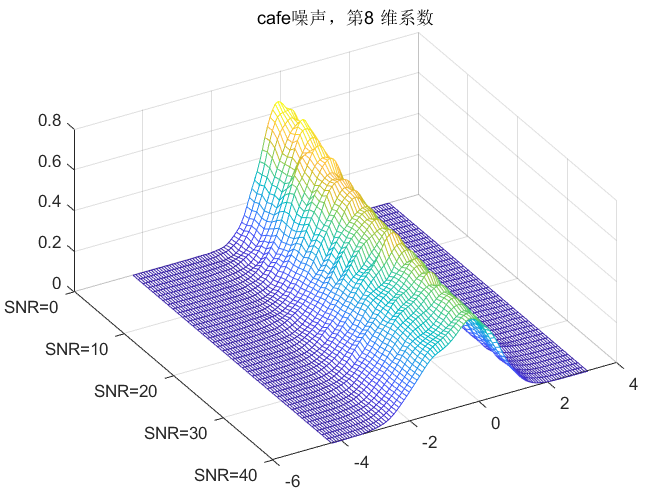
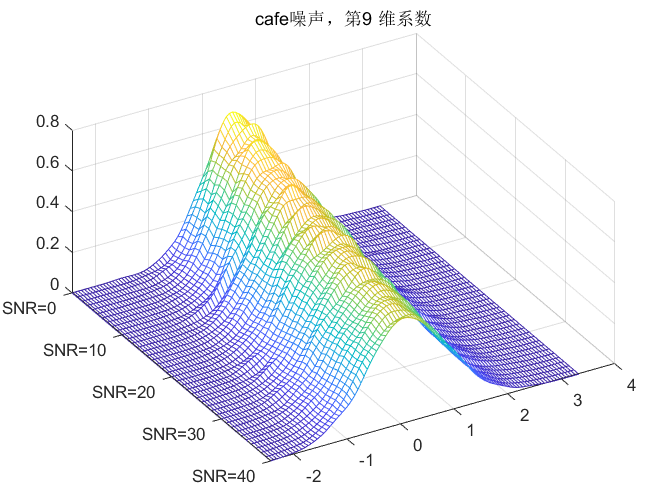
clc;clear all;close all;
MFCC_conf = 'E' ;
SNR = 0 ;
Channel_noise=1 ;
topTraindir = 'C:\Users\wangj\Documents\MATLAB\Experiment05\data';
tic;
k = 2 ;
SNR = 20 ;
save_memory_dim = 1 ;
[clean_cep,noise_cep,trainSpeakerData] = ...
get_noise_MFCC_tmp(topTraindir,save_memory_dim,SNR,MFCC_conf);
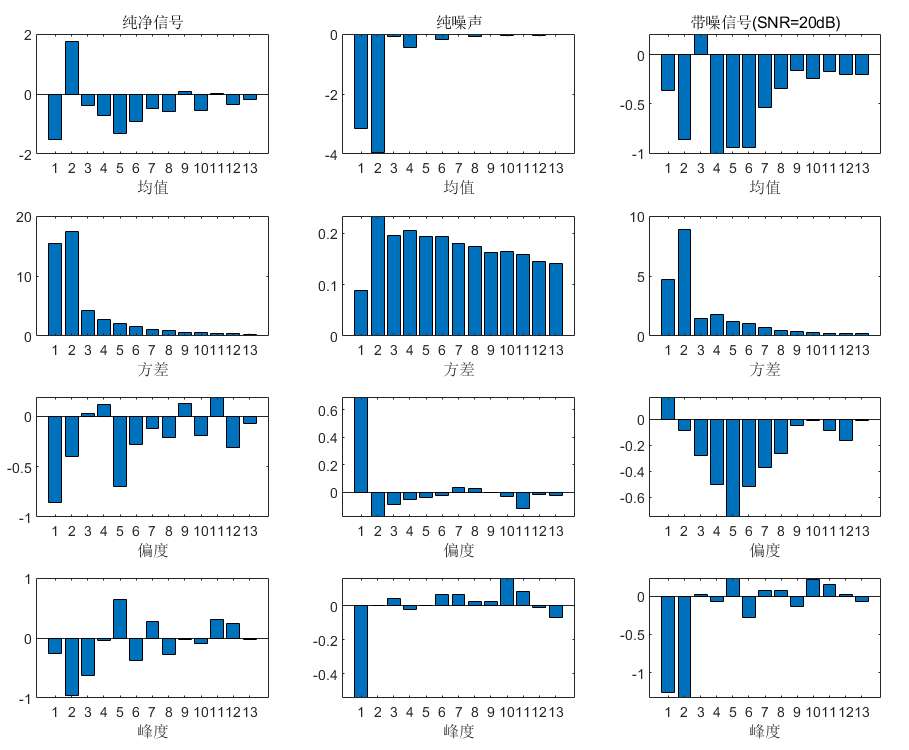
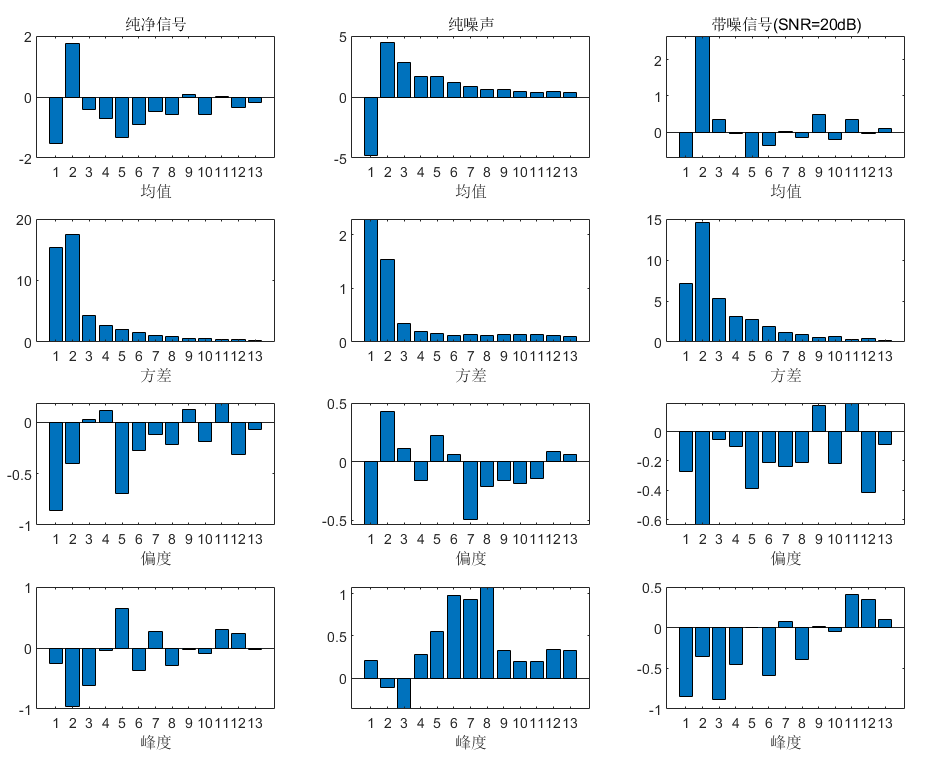
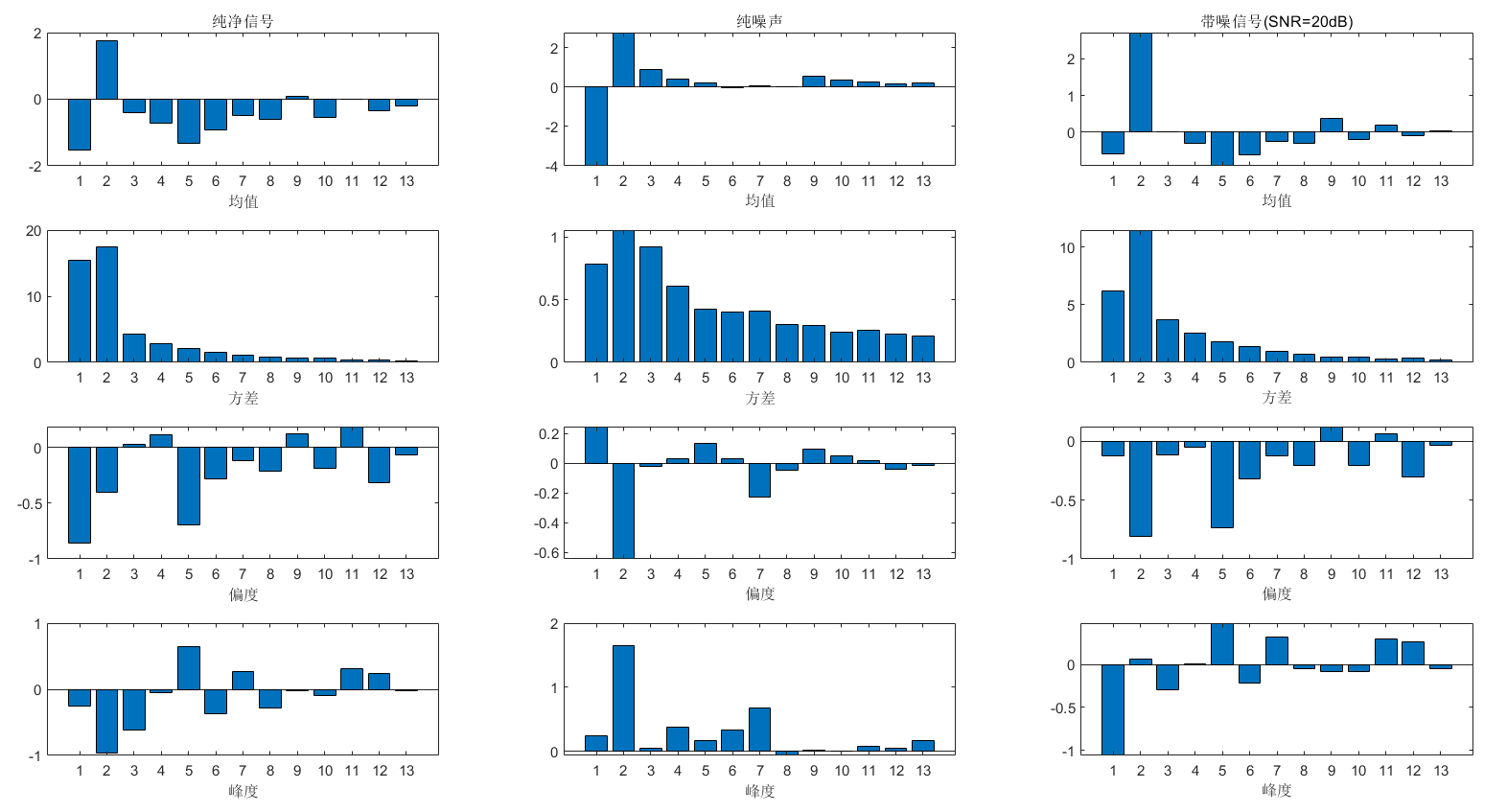
[pdf_by_SNR_1,xi_1] = plot_pdf_2D(clean_cep,k,'w');
[pdf_by_SNR_2,xi_2] = plot_pdf_2D(noise_cep,k,'w');
[pdf_by_SNR_3,xi_3] = plot_pdf_2D(trainSpeakerData,k,'w');
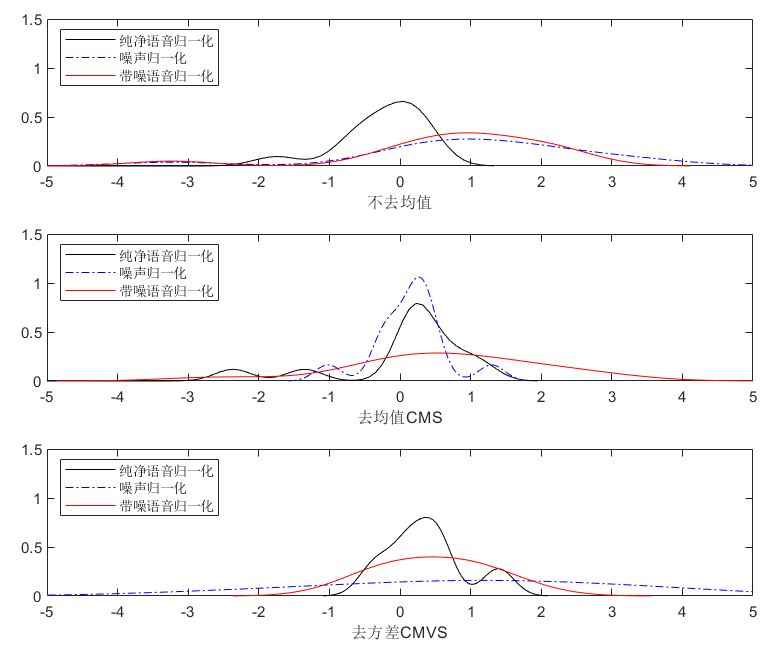
subplot 312;
plot(xi_1,pdf_by_SNR_1,'k');hold on;
plot(xi_2,pdf_by_SNR_2,'b-.');
plot(xi_3,pdf_by_SNR_3,'r');
legend('纯净语音归一化','噪声归一化','带噪语音归一化','location','northwest')
legend('纯净语音归一化','噪声归一化','带噪语音归一化','location','northwest')
xlabel('去均值CMS');
xlim([-5,5]);ylim([0,1.5]);
[pdf_by_SNR_1,xi_1] = plot_pdf_2D(clean_cep,k,'f');
[pdf_by_SNR_2,xi_2] = plot_pdf_2D(noise_cep,k,'f');
[pdf_by_SNR_3,xi_3] = plot_pdf_2D(trainSpeakerData,k,'f');
subplot 311;
plot(xi_1,pdf_by_SNR_1,'k');hold on;
plot(xi_2,pdf_by_SNR_2,'b-.');
plot(xi_3,pdf_by_SNR_3,'r');
legend('纯净语音归一化','噪声归一化','带噪语音归一化','location','northwest')
xlabel('不去均值');
xlim([-5,5]);ylim([0,1.5]);
[pdf_by_SNR_1,xi_1] = plot_pdf_2D(clean_cep,k,'v');
[pdf_by_SNR_2,xi_2] = plot_pdf_2D(noise_cep,k,'v');
[pdf_by_SNR_3,xi_3] = plot_pdf_2D(trainSpeakerData,k,'v');
subplot 313;
plot(xi_1,pdf_by_SNR_1,'k');hold on;
plot(xi_2,pdf_by_SNR_2,'b-.');
plot(xi_3,pdf_by_SNR_3,'r');
legend('纯净语音归一化','噪声归一化','带噪语音归一化','location','northwest')
xlabel('去方差CMVS');
xlim([-5,5]);ylim([0,1.5]);
set(gcf,'color','w');
function [clean_cep,noise_cep,trainSpeakerData] = ...
get_noise_MFCC_tmp(topTraindir,N,SNR,MFCC_conf)
train_wavdir = get_wavdir(topTraindir,N);
nTra_Speakers = size(train_wavdir,1) ;
nTra_Channels = size(train_wavdir,2) ;
trainSpeakerData = cell(nTra_Speakers,nTra_Channels);
noise_cep = cell(nTra_Speakers, nTra_Channels);
clean_cep = cell(nTra_Speakers, nTra_Channels);
for i = 1:nTra_Speakers
for j = 1:nTra_Channels
[x,fs] = readsph(train_wavdir{i,j});
clean_cep{i,j} = v_melcepst(x,fs,MFCC_conf)';
type = 'car' ;
[x,noise] = add_noise_Reality_tmp(x,type,SNR);
noise_cep{i,j} = v_melcepst(noise,fs,MFCC_conf)';
trainSpeakerData{i,j} = v_melcepst(x,fs,MFCC_conf)';
pat = '(?<=\\)[FM].{3}[0-9]' ;
name = regexpi(train_wavdir{i,j},pat,'match') ;
train_SpeakerID{i,j} = name{1} ;
end
end
end
function train_wavdir = get_wavdir(topTraindir,N)
nTra_Channels = 10;
trainFolder = dir(topTraindir);
trainFolder = trainFolder(3:end);
nTra_Speakers = size(trainFolder,1);
train_wavdir = cell(nTra_Speakers, nTra_Channels);
for i = 1:nTra_Speakers
curTraindir = [topTraindir,'\',trainFolder(i).name];%Train子文件夹
trainWav = dir([curTraindir,'\*.WAV']);
for j = 1:nTra_Channels
train_wavname = [curTraindir,'\',trainWav(j).name];%当前wav文件地址
train_wavdir{i,j} = train_wavname;
end
end
train_wavdir = train_wavdir(1:N,:);
end
function [x2,fs] = select_noice(type,Nx)
if type == "cafe"
dir = 'C:\Users\wangj\Desktop\语音识别\different_noise\cafe.wav' ;
elseif type == "car"
dir = 'C:\Users\wangj\Desktop\语音识别\different_noise\car.wav' ;
elseif type =="white"
dir = 'C:\Users\wangj\Desktop\语音识别\different_noise\white.wav' ;
end
[x,fs] = readwav(dir) ;
max_length = length(x);
X = randi(max_length-Nx,1);
x2 = x(X:X+Nx-1);
end
function [y,noise] = add_noise_Reality_tmp(x,type,snr)
Nx = length(x);
[noise,~] = select_noice(type,Nx) ;
signal_power = 1/Nx*sum(x.*x);
noise_power=1/Nx*sum(noise.*noise);
noise_variance = signal_power / ( 10^(snr/10) );
noise=sqrt(noise_variance/noise_power)*noise;
y=x+noise;
end
function [pdf_by_SNR,xi] = plot_pdf_2D(trainSpeakerData,k,flag)
MFCC = cell2mat(trainSpeakerData);
if flag == "w"
MFCC_avg = mean(MFCC');
MFCC_sub = MFCC' - MFCC_avg;
elseif flag == "f"
MFCC_sub = MFCC';
elseif flag == "v"
MFCC_avg = mean(MFCC');
MFCC_sub = MFCC' - MFCC_avg;
MFCC_sub = MFCC_sub./var(MFCC');
end
MFCC_by_SNR = zeros(13,1);
for n = 1 : size(MFCC_sub,2)
MFCC_by_SNR(n) = MFCC_sub(k,n);
end
[pdf_by_SNR,xi] = ksdensity(MFCC_by_SNR);
end
|