K-近邻
算法说明
K近邻的基本算法很好理解:新的样本,由离它近的几个邻居投票决定的。
所以算法就很好写出来了:
- 计算新的样本与所有样本的距离,存在一个变量,假设是A。
- 对A进行排序,选出最近k个距离对应的label标签值。
- 根据lable标签,决定新样本的label
算法优缺点:
优点:
- 对噪声和异常值的容忍度高
缺点:
- 每次对一个未标记的样本都需要计算与已知样本(假设有10万个样本)之间的距离,计算量大。
改进算法
-
增加邻居的权重
假如,我们已知这个身高181,体重80kg的人,有很大概率属于男生,很小概率属于女生。则可以通过
weights参数,加大距离的权重。 -
由以未标记点的指定半径决定近邻,而非距离最近的K个点。由
RadiusNeighborsClassifier实现。 -
K-D Tree:节省计算时间,若C与B很近,A与B很远,则可得A与C也很远,这个时候一定不是邻近点,故可以省略这部分计算。
-
Ball-Tree:在K-D Treee的基础上进一步优化。
Example01:使用K-近邻的算法进行分类
- 通过
make_blobs生成数据集
from sklearn.datasets.samples_generator import make_blobs |
其余的数据集分布为:

-
使用
KNeighborsClassifier进行K-近邻学习,若选择K为5 -
基本的KNN的使用方法:
# 1.指定句柄
k = 5
clf = KNeighborsClassifier(n_neighbors=k)
# 2. 拟合数据,得到训练好的模型
clf.fit(X, y)
# 额外的值可以通过clf.set_params(key=value)设置
# clf.get_params(deep=True)可以查看修改后的参数结果
# 3. 预测数据
y_sample = clf.predict(X_sample)
clf.predict_proba(X_sample)
# 通过 clf.kneighbors(X_sample, return_distance=True) 可以返回【距离和对应K个邻居的索引】
# 用clf.effective_metric_可以查看选择的是距离类型:欧式、曼哈顿等
# 4. 评价数据的结果
clf.score(X_test,y_test)
Example02:使用K-近邻的算法进行回归
-
使用
KNeighborsRegressor进行K-近邻的回归拟合 -
基本的KNN回归的使用方法:
from sklearn.neighbors import KNeighborsRegressor
# 1. 指定句柄
k = 5
knn = KNeighborsRegressor(k)
# 2. 拟合数据
knn.fit(X,y)
# 3. 拟合曲线
# 3.1 拟合曲线的X轴的范围
T = np.linspace(0,5,500)[:,np.newaxis]
# 3.2 预测
y_pred = knn.predict(T)
# 4. 生成拟合的准确性
knn.score(X,y)
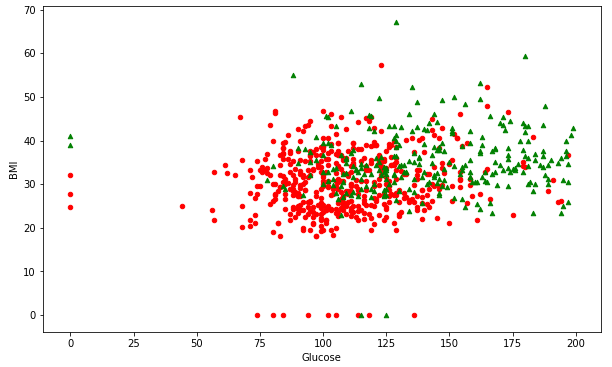
Example03:糖尿病的预测
数据预处理
-
使用pandas读入数据csv
pd.read_csv('.csv')
-
对于DataFrame数据,可以使用.groupby进行聚类分析,输出的类型为:DataFrameGroupBy
<pandas.core.groupby.groupby.DataFrameGroupBy object at 0x0000016B0697A898>可以接下进行统计操作:
.sum().mean().size() -
划分数据:
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2);
模型训练
-
模型比较:
K-近邻算法;带权重的K-近邻算法;指定半径的K-近邻算法from sklearn.neighbors import KNeighborsClassifier, RadiusNeighborsClassifier
models = []
models.append(("KNN", KNeighborsClassifier(n_neighbors=2)))
models.append(("KNN with weights", KNeighborsClassifier(
n_neighbors=2, weights="distance")))
models.append(("Radius Neighbors", RadiusNeighborsClassifier(
n_neighbors=2, radius=500.0))) -
测试结果为:
name: KNN; score: 0.6688311688311688
name: KNN with weights; score: 0.6558441558441559
name: Radius Neighbors; score: 0.6233766233766234
由于使用了test_train_split()产生了随机性,上面的结果并不准确和稳定,应该多次随机分配训练数据集和交叉验证集
解决方法:使用接口:KFlod和cross_val_score()
-
KFlod 随机划分测试集和训练集,n_split 可以设置几次随机。也即分成几分。
分三折,就需要进行三次测试。故这里:折数 = 随机数
故这里不需要设置 train_test_split 里面的train_size的值,因为这个值相当于自动计算出来的。 -
cross_val_score()可以组合这些score,最后求平均值⭐️这里有个技巧,利用列表缓存结果:
results = []
for name, model in models:
kfold = KFold(n_splits=10)
cv_result = cross_val_score(model, X, Y, cv=kfold)
results.append((name, cv_result))最终得到的结果:
[('KNN', array([0.66233766, 0.77922078, 0.66233766, 0.71428571, 0.7012987 ,
0.77922078, 0.77922078, 0.76623377, 0.69736842, 0.71052632])), ('KNN with weights', array([0.71428571, 0.72727273, 0.64935065, 0.68831169, 0.7012987 ,
0.7012987 , 0.68831169, 0.7012987 , 0.61842105, 0.71052632])), ('Radius Neighbors', array([0.58441558, 0.71428571, 0.55844156, 0.61038961, 0.64935065,
0.61038961, 0.81818182, 0.67532468, 0.68421053, 0.60526316]))]需要:
results[i][1].mean()name:
KNN; cross val score: 0.7147641831852358
name: KNN with weights; cross val score: 0.6770505809979495
name: Radius Neighbors; cross val score: 0.6497265892002735
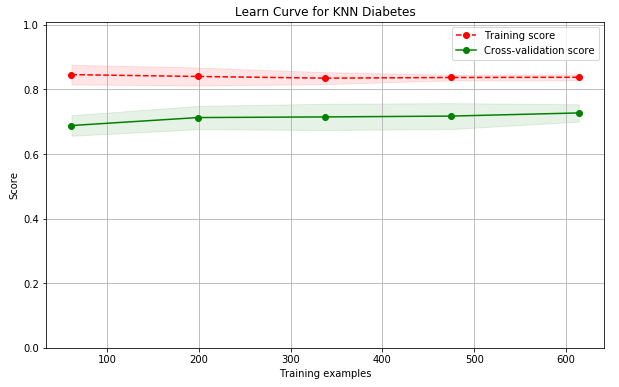
结果分析与模型改进
knn.score():可以输出训练集和测试集的得分结果。
通过绘制学习曲线,可以更好的分析结果:
Example04:数据可视化:SelectKBest
选择相关性最大的两个特征
相关性:
- 卡方值的大小可以反映变量与目标值的相关性
sklearn.feature_selection.chi2()- F值检验,
sklearn.feature_selection.f_classif
from sklearn.feature_selection import SelectKBest |