
 第7章决策树
第7章决策树
原理说明:
# DecisionTreeClassifier
from sklearn.tree import DecisionTreeClassifier
decision_tree = DecisionTreeClassifier(criterion='gini', splitter='best', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort='deprecated', ccp_alpha=0.0)
2
# Attribute:
criterion: 特征选择算法。
gini基尼系数,entropy信息熵。有研究表明,两个算法的差距不是很大,相比较而言,信息熵的运算效率会低一点,因为信息熵的公式中存在对数运算。
splitter:
best和random两个属性默认是
best:正常都是选择最优的分支创建原则。但是还提供了一个过拟合的接口random,从表现最优的几个特征中随机选择一个特征来创建分支。前剪枝的属性控制:- max_depth: 设置最大深度
- min_samples_split: 创建分支的数据集
- max_samples_leaf:
- max_leaf_nodes: 最大样本节点的个数
- min_impurity_split: 信息增益的阈值。
# 额外问题记录:
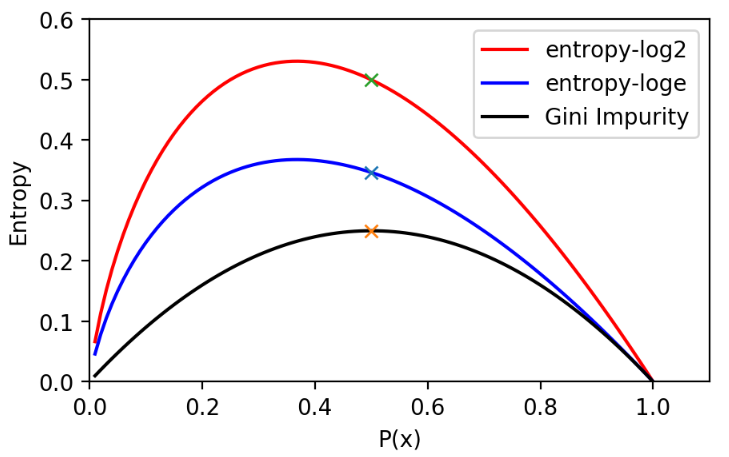
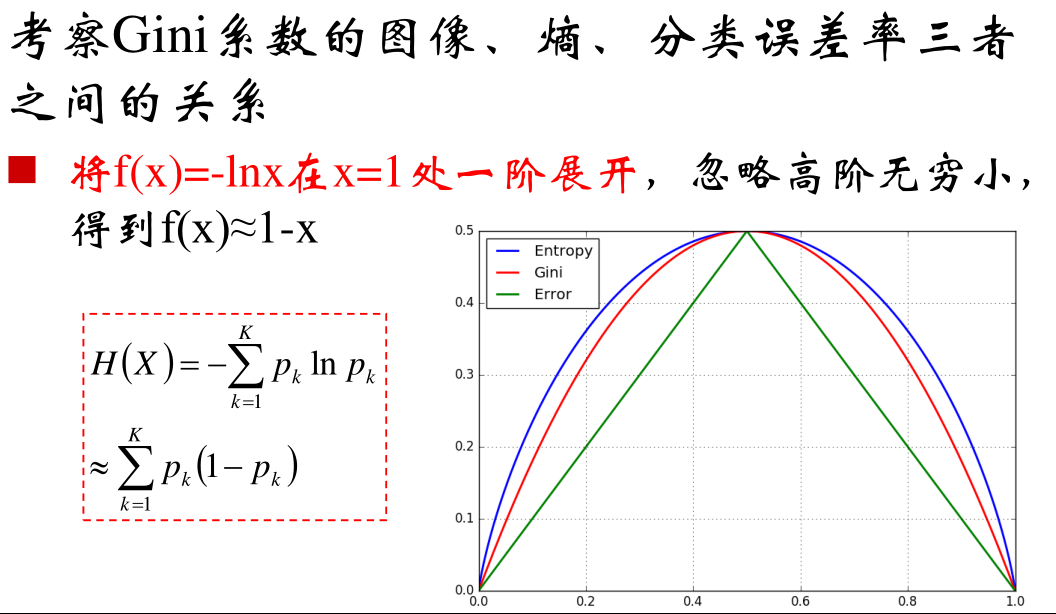
原理部分在西瓜书中已经讲的很清楚了,所以原理部分直接跳过,这里有个疑惑在于,这本书的熵值曲线图与邹博给出的图不同,这里记录一下。
不同点一:
正统的熵值对数取的底是2 ,所以最终计算出的熵值单位是
bit不同点二:熵值曲线最大值并不是在概率等于0.5的情况,邹博那种图说的通,但是不知道怎么画出来的??
| Example01——熵 (opens new window) | 邹博提供 |
|---|---|
 |  |
记录书中的一段比较好的话:
增熵原理就是鼓励热力学系统的熵不减少,总是增大或者不变。一个鼓励系统不可能朝低熵的状态发展,即不会变得有序。
如果没有外力的作用,这个世界将是越来越无须的。人或者,在于尽量让熵变低,即让世界变得更有序,降低不确定度。当我们在消费资源时,是一个增熵的过程。我们把有序的食物变成了无序的垃圾。例如,笔者在写书或读者在看书的过程,可以理解为减熵过程。我们通过写作和阅读,减少了不确定的信息,从而实现了减熵的过程,人生价值的实现,在于消费资源(增熵过程)来获取能量,经过自己的劳动付出(减熵过程),让世界变得更加纯净有序,信息增益(减熵量-增熵量)即是衡量人生价值的尺度。希望笔者在暮年之时,回首往事,能自信地说,我给这个世界带来的信息增益是正数,且已经尽力做到最大了。
# Example: 预测泰坦尼克号幸存者 (opens new window)
泰坦尼克号dataset重点在于预处理。
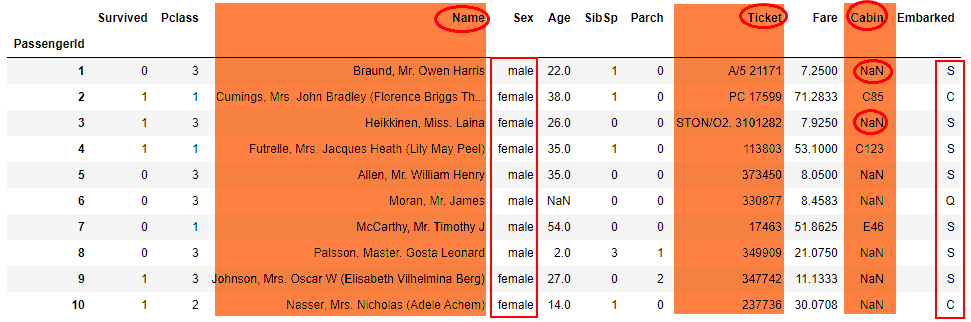
- 读入数据:
train = read_dataset('datasets/titanic/train.csv')
数据清洗:
需要删除
Name、Ticket、Cabin三个标签,inplace可以设置内存覆盖。data.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)1对于Sex 希望转换成
int数据,将bool型数据转换为intdata['Sex'] = (data['Sex'] == 'male').astype('int')1但是只能转换
0/1分类标签。Embarked :是港口信息,需要转换为多分类的标签
In [4]: labels = data['Embarked'] ...: labels.unique() Out[4]: array(['S', 'C', 'Q', nan], dtype=object) In [5]: labels.unique().tolist() Out[5]: ['S', 'C', 'Q', nan] In [6]: data['Embarked'].apply(lambda n: labels.tolist().index(n)).head(10) Out[6]: PassengerId 1 0 2 1 3 0 4 0 5 0 6 5 7 0 8 0 9 0 10 1 Name: Embarked, dtype: int641
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21可以发现数据中还存在
NAN值,可以转换为0data = data.fillna(0)1
结果显示:
In [8]: data.head(10) Out[8]: Survived Pclass Sex Age SibSp Parch Fare Embarked PassengerId 1 0 3 1 22.0 1 0 7.2500 0 2 1 1 0 38.0 1 0 71.2833 1 3 1 3 0 26.0 0 0 7.9250 0 4 1 1 0 35.0 1 0 53.1000 0 5 0 3 1 35.0 0 0 8.0500 0 6 0 3 1 0.0 0 0 8.4583 2 7 0 1 1 54.0 0 0 51.8625 0 8 0 3 1 2.0 3 1 21.0750 0 9 1 3 0 27.0 0 2 11.1333 0 10 1 2 0 14.0 1 0 30.0708 11
2
3
4
5
6
7
8
9
10
11
12
13
14代码封装:
def read_dataset(fname):
# 指定第一列作为行索引
data = pd.read_csv(fname, index_col=0)
# 丢弃无用的数据
data.drop(['Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 处理性别数据
data['Sex'] = (data['Sex'] == 'male').astype('int')
# 处理登船港口数据
labels = data['Embarked'].unique().tolist()
data['Embarked'] = data['Embarked'].apply(lambda n: labels.index(n))
# 处理缺失数据
data = data.fillna(0)
return data
train = read_dataset('datasets/titanic/train.csv')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
结果分析
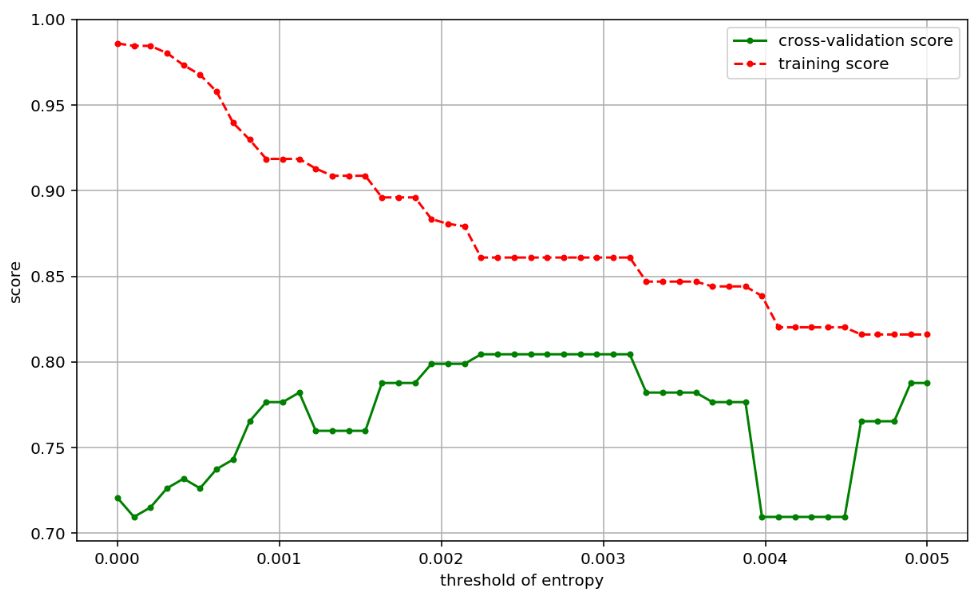
- 通过 最大的决策树的深度可以发现结果最好的是 5
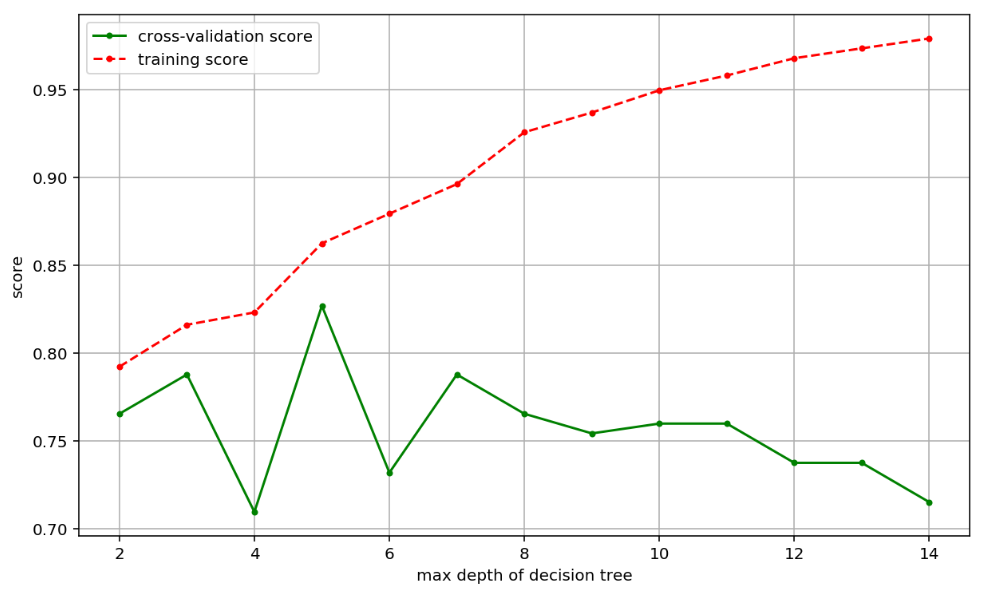
决策树还可以设置交叉熵的截止阈值
可以发现在交叉验证集中有一个断崖式的下降,可以设置阈值。
通过安装 可以显示决策树。
from sklearn.tree import export_graphviz with open("titanic.dot", 'w') as f: f = export_graphviz(clf, out_file=f) # 1. 在电脑上安装 graphviz # 2. 运行 `dot -Tpng titanic.dot -o titanic.png` # 3. 在当前目录查看生成的决策树 titanic.png1
2
3
4
5
6
7
8显示效果:
# 集合算法【Ensemble】
Bagging算法
- 有放回的重采样
- 并行计算,速度快
- 【经典】随机森林
RandomForestClassifier:取t棵树的平均值--回归问题RandomForestRegressor:少数服从多数的投票原则--分类问题
boosting算法
- 针对预测错误的样本进行加权处理
- 串行计算,速度慢
- 实现方法
AdaBoost算法AdaBoostClassifier分类函数AdaBoostRegressor回归函数
ExtraTress算法:
- 直接从这些特征里随机选择一个特征来分裂,从而避免过拟合问题。
- 算法
- 分类:
ExtraTreesClassifier - 回归:
ExtraTreesRegressor
- 分类:
随机森林的有效性说明:
- 若使用所有特征进行分类训练,假设存在某个特征对预测结果有强关联。如果选择全部的特征,则这个特征在所有的决策树中体现。故最终的结果会与这个强预测特征受影响。容易过拟合。
- 随机森林,确保了每个特征都对预测结果有少量的贡献,从而避免单个特征对预测结果有过大的贡献导致的过拟合问题。