前言
机器学习算法中经常需要求解凸函数的极值求解问题,一般来说解析解是很难求得的,或者即使有解析解,出于某种原因(比如计算量过大,矩阵求逆等)也不会使用解析解。之前学习skleran库时LogisticRegression函数中有个solver参数,可以设置逻辑回归损失函数的优化方法,又牵涉到这部分的内容,所以这里做个总结
| 参数 |
说明 |
lbfgs |
拟牛顿法 |
newton-cg |
牛顿法家族的一种 |
sag |
随机平均梯度下降 |
牛顿法
牛顿法求根
使用函数的泰勒级数前面几项来找方程 f(x)=0的根。
注:x=[x1,x2,…,xn]是n维空间向量。将函数在其根的附近进行泰勒展开:
f(x)=f(x0)+f′(x0)(x−x0)+21f′′(x0)(x−x0)2+Rn(x)
设x=xt时,是函数f(x)的根,即f(xt)=0,若设xk为xt的估计值。首先我们在x=xk处进行泰勒一阶展开,得:
f(x)=f(xk)+f′(xk)(x−xk)+Rn(x)≈0+f′(xk)(x−xk)
根的迭代方式为:
x=xk+f′(x)f(x)
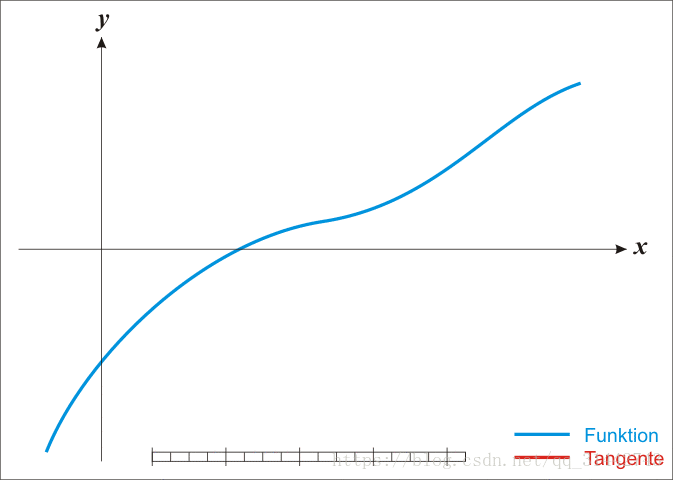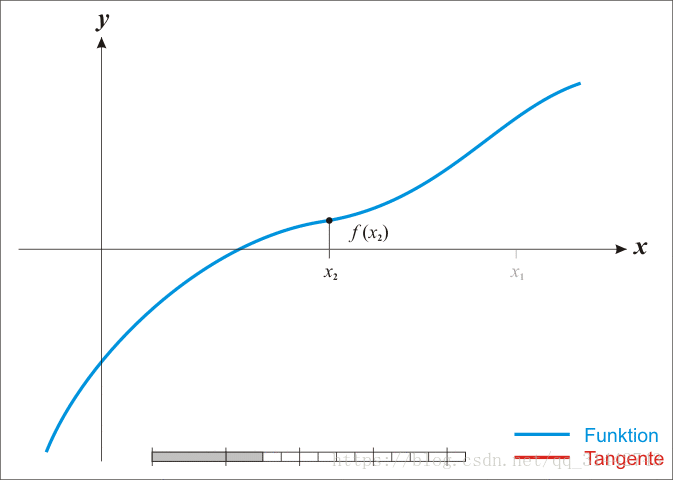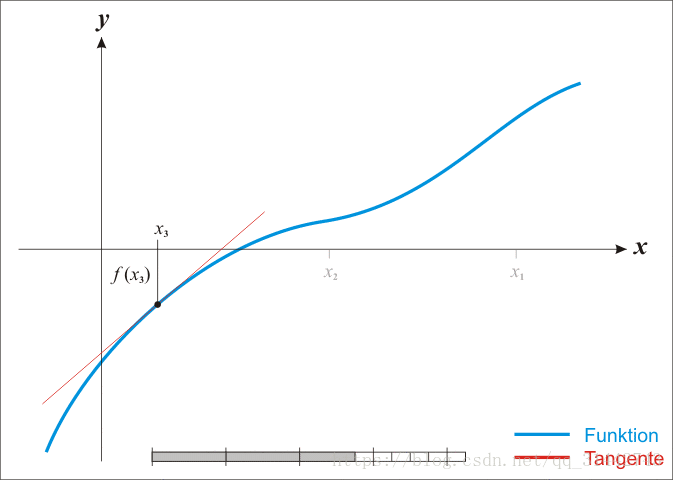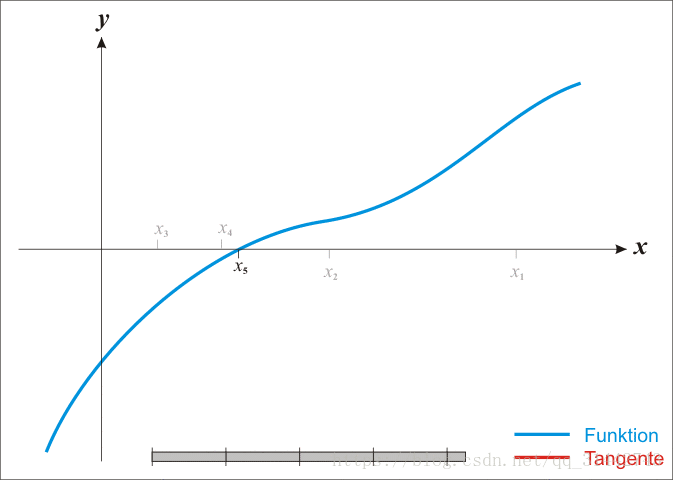
迭代过程图,见下:
![]()
观察根的迭代方式,此方法也被称作为切线法。
牛顿法求驻点
其需要解决的问题可以描述为:对于目标函数f(x),在无约束条件的情况下求它的最小值。
x∈Rnminf(x)
牛顿法求驻点,需要用到二阶导函数,从简单的开始分析,设置n为x的维度。
当n=1时
设x=xt时,函数f(x)取得最小值,目标希望求得xt,若设xk为xt的估计值。首先我们在x=xk处进行泰勒二阶展开,得:
f(x)=f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2+Rn(x)≈f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2
对f(x)求导,得:
f′(x)=f′(xk)+f′′(xk))(x−xk)
令f′(x)=0,得:
x=xk−f′′(xk)f′(xk)
当n>1时:牛顿-拉夫森迭代法(Newton-Raphson method)
当x为高维向量时,对f(x)对x的一阶导数是一个向量,对x的二阶导数为N∗N的矩阵【海塞矩阵】。
f′(x)=f′′(x)==(∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x))[∂xi∂xj∂2f(x)]n×n⎣⎢⎢⎢⎢⎢⎡∂x12∂2f∂x2∂x1∂2f⋮∂xn∂x1∂2f∂x1∂x2∂2f∂x22∂2f⋮∂xn∂x2∂2f⋯⋯⋱⋯∂x1∂xn∂2f∂x2∂xn∂2f⋮∂xn2∂2f⎦⎥⎥⎥⎥⎥⎤
为了便于表达,其中gk是向量,Hk为海塞矩阵
则高维向量的迭代公式为:
xk+1=xk−Hk−1gk
以上被称为原始的牛顿迭代法,迭代格式中的搜索方向为dk=−Hk−1⋅gk称为牛顿方向。
算法流程
设置导函数的终止阈值a,当∥f′(xk)∥<a时,则停止计算。得到x=xk即为所求。
- 给定初值x0和精度阈值ϵ,并令 k:=0
- 计算gk和Hk
- 若 ∥gk∥<ϵ,则停止迭代;否则确定搜索方向dk=−Hk−1⋅gk
- 计算新的迭代点xk+1:=xk+dk
- 令k:=k+1,循环第2步。
可以发现原始牛顿法迭代公式中没有步长因子,而是定步长迭代,对于非二次型目标函数,有时会使函数值上升,即出现f(xk+1)>f(xk)的情况,这时,牛顿法不能收敛,从而导致计算失败。对于这种情况,可以使用阻尼牛顿法来解决。
阻尼牛顿法
阻尼牛顿法的思想很简单,既然传统的牛顿法迈的步子太大(定步长),那我就人为的设置一个参数去控制你这个步子,即步长因子λk。每次迭代方向与原始牛顿法的方向相同,但是迭代前先找到最优的步子的大小,即
λk=argλ∈Rminf(xk+λdk)
算法流程相较于原始牛顿法,只需要修改第四步的迭代方式:
xk+1=xk+λkdk
算法总结与分析
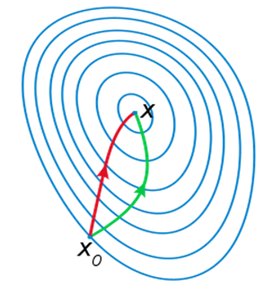
牛顿法是梯度(下降)法的进一步发展,梯度法利用目标函数的一阶偏导数信息、以负梯度方向作为搜索方向,只考虑目标函数在迭代点的局部性质;而牛顿法不仅使用目标函数的一阶偏导数,还进一步利用了目标函数的二阶偏导数,这样就考虑了梯度变化的趋势,因而能更全面地确定合适的搜索方向以加快收敛,它具二阶收敛速速度。
![]()
给出梯度下降的一阶Taylor近似:
f(x)≈f(xk)+f(xk)T(x−xk)
给出二阶Taylor近似:
f(x)≈f(xk)+f′(xk)(x−xk)+21f′′(xk)(x−xk)2
对于点xk,不同方法的下降方式:
⎩⎪⎪⎨⎪⎪⎧−f˙(xk)−f¨(xk)−1f˙(xk)λk[−f¨(xk)−1f˙(xk)]gradient descentNewton−Raphsondamping Newton−Raphson
但牛顿法主要存在以下两个缺点:
- 对目标函数有较严格的要求。函数必须具有连续的一、二阶偏导数,海森矩阵必须正定.
- 计算相当复杂.除需计算梯度而外,还需计算二阶偏导数矩阵和它的逆矩阵.计算量、存储量均很大,且均以维数N的平方比增加,当N很大时这个问题更加突出。当Hessian矩阵不是很大时牛顿方法要优于梯度下降。
其余内容(非重点)
拟牛顿法
逆牛顿法主要解决计算条件苛刻以及计算量大等问题,当海森矩阵无法保持正定,不用二阶偏导数构造出可以近似海森矩阵或者海森矩阵的逆的正定对称矩阵。不同构造方法,产生不同过得拟牛顿法。更多资料请见参考资料【2】,内容太数学了,学了也没什么必要,等接触到再说把。
重新叙述一遍算法:
f′(x)≈f′(xk)+f′′(xk))(x−xk)
引入记号,gk和Hk
gk+1−gk≈Hk+1(xk+1−xk)
再引入记号sk和yk
sk=xk+1−xk,yk=gk+1−gk
可写:
yk≈Hk+1⋅sk
牛顿法计算平方根
算法:
f(x)=x2−a=0f′(x)=2xxn+1=xn−f′(xn)f(xn)=xn−2xnxn2−a=2xn2xn2−(xn2−a)=2xn+2xna
程序语言:
xn:=2xn+2xna=xn/2+a/2/xn
参考资料:
- 牛顿法的具体推导–CSDN
- 牛顿法系统性介绍–CSDN
- 博客园–桂
- LogisticRegression参数详解