本文的主要知识点:第一部分讲对Logistics的概念理解。第二部分讲公式推导,主要从两个角度去思考,其一、从广义线性模型的角度出发推导公式,另一点从伯努利分布推导。
第一部分 对Logistics的概念理解
线性回归的非线性映射
早就听说过Logistics回归做的是分类的活,而非字面意思上的回归,那它和回归有什么关系呢?
在上一篇的线性回归模型中已经讲过一个观点,为什么线性回归是属性特征的线性组合呢?
- 其一是ω能够直观的显示出各个属性的权重大小,
- 其二就是模型足够简单,可以在线性回归模型的基础上增加高维映射变为非线性模型。
如:
y=wTx+b
若预测值非线性变换,而是指数变换,换句话说就是预测值的对数是线性变换,如下:
lny=wTx+b
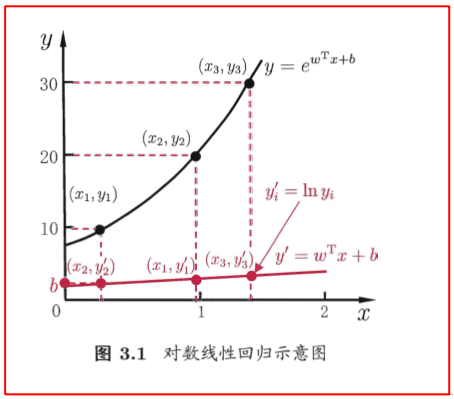
下图可以看作线性预测值 y′ 进行非线性 y 的映射:
yi=eyi′=ln−1(yi′)
![]()
上述映射是“广义线性模型”的特殊形式:
y=g−1(wTx+b)
g(⋅)是联系函数,要求连续且充分光滑,上例是g(⋅)=ln(⋅)的特例。
Logistics的核心是分类,但为啥叫回归?
若是要做二分类:最简单的方式是阶跃函数
y=⎩⎨⎧0,0.5,1,wTx+b<0wTx+b=0wTx+b>0
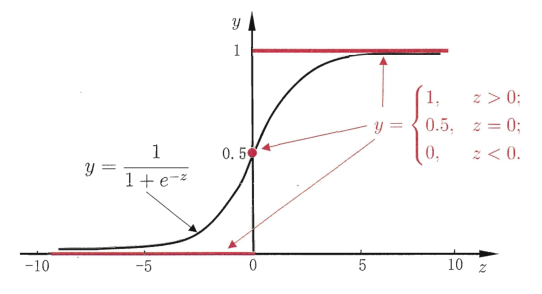
但是阶跃函数有个致命的缺点:不可导。尤其在深度学习中,反向传播过程中需要对函数进行反向求导。所以提出了一个替代函数对数几率(odd)函数(logistic function):
y=1+e−z1=1+e−(wTx+b)1
上述函数也称为sigmoid函数:
![]()
将sigmoid函数进行某种转换,结合第一节内容对比:
ln1−yy=wTx+b
这个公式解释了为啥叫回归,仅是与线性回归公式很像,实际上做的是回归后的预测值分类问题
注:sklearn中调用LogisticsRegression这个函数,返回值coef_就是这里的ω
第二部分 Logistics回归公式推导
上面介绍了Logistics回归的本质就是:线性模型+sigmoid函数(非线性映射),只是说了这样可以拟合出指数级别y的变化。而为何Logistics回归是这种组合,以及如何利用样本去训练二分类模型却没有说明。
Φ=1+e−wTx1
argminwi=1∑N[yilogp(y=1∣x)+(1−yi)logP(y=0∣x)]
第一个公式推导怎么来的?
要了解广义线性模型必须先要知道两个概念。指数族分布以及需要满足的三条假设。
知识点一:指数族分布律
需满足以下分布律才可以称为指数族:
p(y;η)=b(y)exp(ηTT(y)−a(η))
其中a(η)是配分函数,使得分布律最大为1, η是该分布的自然参数,T(y)是充分统计量。
说明1:伯努利分布是指数族分布
伯努利分布(Bernoulli distribution)又名两点分布或0-1分布,介绍伯努利分布前首先需要引入伯努利试验(Bernoulli trial)。
伯努利试验都可以表达为“是或否”的问题。例如,抛一次硬币是正面向上吗?刚出生的小孩是个女孩吗?等等
-
如果试验E是一个伯努利试验,将E独立重复地进行n次,则称这一串重复的独立试验为n重伯努利试验。
-
进行一次伯努利试验,成功(X=1)概率为p(0<=p<=1),失败(X=0)概率为1-p,则称随机变量X服从伯努利分布。伯努利分布是离散型概率分布,其概率质量函数为:
f(x)=px(1−p)1−x=⎩⎨⎧p1−p0x=1x=0其他
故根据上述伯努利分布的定义则有:
p(y)===Φy(1−Φ)1−yexp(ln(Φy(1−Φ)1−y))exp(y⋅ln(1−ΦΦ)+ln(1−Φ))
与指数族的定义比对:p(y;η)=b(y)exp(ηTT(y)−a(η))
得伯努利确实是指数分布:
b(y)=T(y)=η=a(η)=1yln(1−ΦΦ)−ln(1−Φ)=ln(1+eη)
知识点二:广义线性模型需要的三条假设
- 给定x,y需服从于指数族分布(以满足)
- 给定x,训练后的模型等于充分统计量的期望:h(x)=E[T(y∣x)]
- 自然参数η ,需和观测变量x呈线性关系:η=wTx
根据第一条,伯努利分布是成功(X=1)概率为p,失败(X=0)概率为1-p。对于本例中二分类问题的标签分别为0/1,若设置1的概率为p,0的概率为1-p,很明显看得出标签为0,1分布的二分类问题就是典型的伯努利分布。
根据第二条:
h(x)==E[T(y∣x)]E[y∣x]=1×p(y=1)+0×p(y=0)=p(y=1)=Φ
又:
η=ln(1−ΦΦ)⇒Φ=1+e−η1
根据第三条:η=wTx 代入上式
综上:
Φ=1+e−wTx1
第二公式:模型是怎么训练的?
核心可以总结为下面的公式:
(min)MLE⇔(min)Loss function[CrossEntropy]
训练模型从优化的角度需要提出个损失函数,让这个损失函数最小。同样的也可以从模型生成的角度出发,让标签出现的概率最大。所以上述的这个公式很好的展现了模型如何训练才可被得到。
这里从模型生成的角度出发来解释问题,首先要提出p(y∣x;w)的表达式,有两种表达式见下分析。
标签y的分布律为:
在此之前明确的是:
- y是离散值,只有{0,1}两个标签
- sigmoid输出的是标签的概率,是(0,1)之间的连续值。
一开始很不理解:y(y=1∣x)=σ(wTx)=1+e−wTx1 以及y(y=0∣x)=σ(wTx)=1+e−wTxe−wTx 这两个公式,其实很好理解σ(z)的输出假设为0.1,…,0.6,0.9。输出的值越大,离1越近,则被分为1的概率越大。所以自然而然地将(y=1)的概率视为σ(wTx)。【即,也就是之前说的概率属性的含义】
西瓜书版:
P(y∣x;β)=y⋅P(y=1∣x;β)+(1−y)⋅P(y=0∣x;β)
吴恩达讲课版:
P(y∣x;β)=[P(y=1∣x;β)]y⋅[P(y=0∣x;β)]1−y
注1:西瓜书和吴恩达对上面两个公式的融合的手段不一样,但是最后可以发现上述两个式子,很好的整合了y=1和y=0两种情况,自己代入检验一下。
注2:周志华版西瓜书中的公式推导太复杂,吴恩达版公式非常好推,也是经常见到的推导过程。
无论采用上面哪儿一个概率表达式,最后都可以利用极大似然概率估计【MLE】推出w的:
argmaxwlogp(y∣x)===argmaxwi=1∑Nlogp(yi∣xi)argmaxwi=1∑N[yilogp(y=1∣x)+(1−yi)logP(y=0∣x)]argminw−(i=1∑N[yilogp(y=1∣x)+(1−yi)logP(y=0∣x)])=argminwCross Entropy
总结:
-
极大似然估计就是找到能让y观测变量出现概率最大的模型参数β【即w】
-
Logistics回归的模型参数的方法有两个:最大化样本出现的概率和最小化交叉熵。两个方法分别是从两种角度建模,模型生成角度和优化角度。
⭐️注3:这里的p(yi∣xi)只是形式上的表达,并非代表条件概率,真正的条件概率实为p(yi∣w)。因为已知xi必然已知yi,推导过程中也没有用到贝叶斯公式,算是之前理解的一个坑把。
额外知识点:sigmoid函数的求导(自证)
易证:其中单引号表示对x求导
σ(z)’=σ(z)(1−σ(z))