
选择爬取的网站为英文小说网站:http://www.hiwuxia.com/
这种类型的网站访问量小,所以反爬措施也比较少,非常作为新手爬虫网站。
网站F12解析
- 基本元素说明:
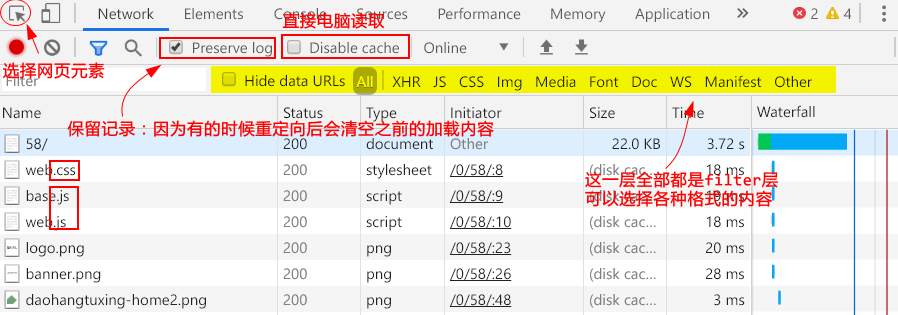
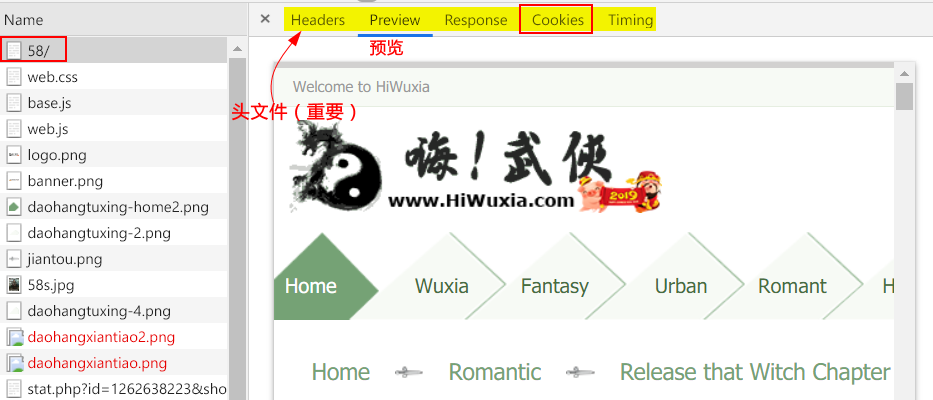
- Headers:重要内容
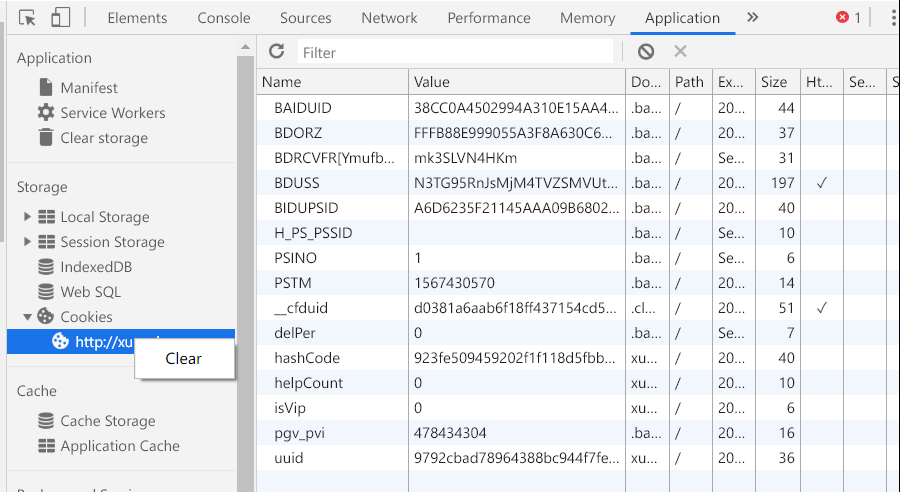
- 如何清空 Cookie
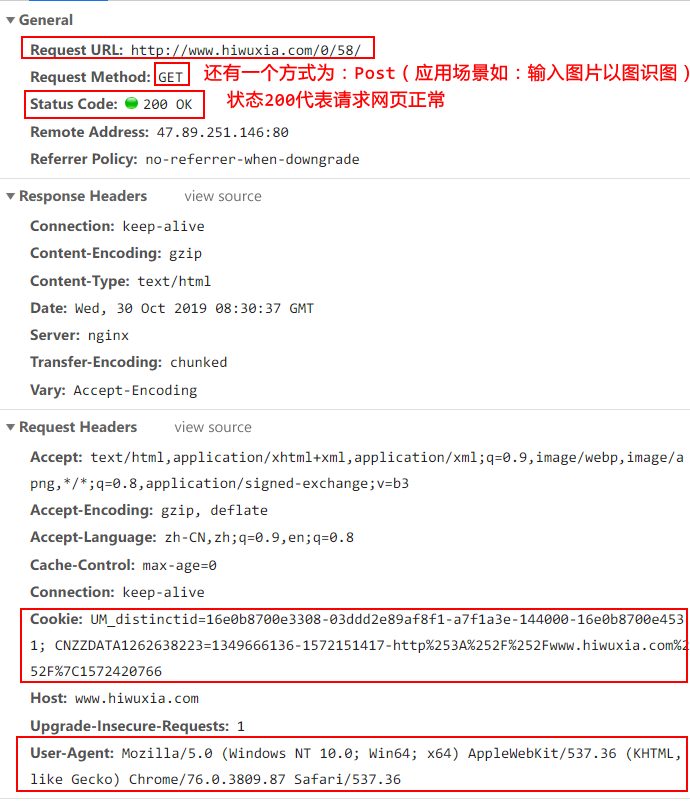
第一次请求,会设置set Cookie 等相关内容存储在本地(如Cookie 有生命周期,属性为:Expires =)
Session–服务器(会定时清理)
Cookie–客户端(本地)
每个Cookie都有一个Value,服务器接收到Cookie会对Value进行解析,一般情况下Cookie的生命周期都为999,但是Session会进行定时清理,所以Cookie有效性不会很长。
具体详细信息可以通过application查看
注1:如果我们爬取下的html文件在无网络下打开,格式会出错的原因在于,很多图片和元素都是类似于图床模式需要网络情况下加载。还有一部分文件采用的url是相对路径,存储在某个不知名的路径中,所以即使在有网络的情况下,爬取的html文件与我们看到的网页仍有差异。
开始爬取小说
第一步:爬取子网页的url信息
通过右键,查看查看网页源代码
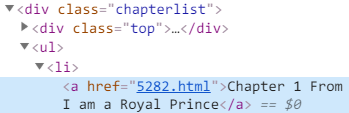
查找章节信息在html的位置: Chapter 1 From today onwards, I am a Royal

发现章节内容是包含在<class=“chapterlist”>这个节点下面的。此外,Chapter 1的子网页名为:http://www.hiwuxia.com/0/58/5282.html,所以我们要提取的内容是这个元素。
故总结提取路径为:<div class=“chapterlist”> –> <ul> –><li> –><a href=…>
 )
)
- 使用Chrome插件工具

//div[@class="chapterlist"]/ul/li//@href |
- 在py文件中需要导入etree库
from lxml import etree |
注意的是此时html不是简单的url网址:http://www.hiwuxia.com/0/58/
而是html = requests.get(url).text
因为模拟的步骤是:chrome游览器下ctrl + u 查看源码【requests.get(url).text】,在源码中查找【xpath语法/或使用正则化re也行】章节信息这个操作。
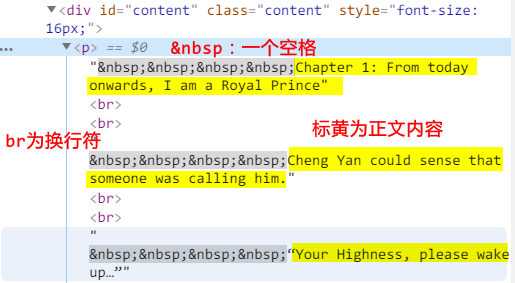
第二步:爬取子网页中的content
过程方法同上:通过F12查找到正文内容在Html文件中的位置,代码引入xpath语法,筛选出相应的内容。
-
网页端插件
![]()
-
py文件中的语法:
//div[@class="content"]//text()
注2:此时通过xpath得到的是一段一段的内容,以<br>为界,所以需要通过
''.join(content)链接内容,双引号里头的内容为划分字符,这里是空格。也可以为'\n'.join链接字符为换行。

a = ['1','2','3'] |
第三步:存储文本
语法为with open('文件路径/文件名','a+') as f:其中a+代表追加模式
注3:爬虫的需要引入time模块,控制爬取的速度不能太快
with open('./release that witch.txt','a+') as f : |
完整代码:
#!/usr/bin/env python3 |
